
240+ AI Tools That Defined 2025
Categorized roundup of the year’s most impressive generative models and tools.

Prior version of this article first appeared as a guest post for AI Supremacy.
I co-wrote this post with Charlie Guo (Artificial Ignorance) in early June 2025:
Now that the year is almost over, I want to revisit our original mid-year roundup and add a supplemental bullet list for each section to include any noteworthy updates.
Note: In most cases, my supplemental list is longer than the one in our original article, which shows just how intense the pace of releases is in generative AI.
I deliberately chose to keep our original list fixed, so when you see us talk about “the best model or tool,” it’s more than likely that it’s been surpassed since then (especially when it comes to AI image and video models).
Enjoy!
The avalanche of AI advances is enough to give anyone whiplash.
New models, features, and tools are launched daily.
It’s impossible to keep track of it all.
So to help you get your bearings, we put together this list of all the noteworthy launches of early 2025, split into the following categories:
Chatbots & traditional LLMs
Reasoning models
Research tools
Coding
Browser agents
Image generation
Video generation
Music creation
Voice
3D generation
Note that this list includes only tools and models that either first came out or received major features/upgrades in 2025.
Let’s dive in!
🗣️ 1. Chatbots & traditional LLMs
2025 is the year of reasoning models that work methodically through tasks and display their thinking process. But that’s not to say that regular conversational models are standing still.
Best overall: GPT‑4.1 (OpenAI)
GPT-4.1 is strictly a better version of the default GPT-4o model in ChatGPT.
It’s the smartest non-reasoning model and a decent coder with access to all ChatGPT tools, including Canvas, image generation, file and photo analysis, etc.
GPT-4.1 also has a 1-million-token context window, making it great for analyzing long documents or handling multiturn chats.
All the rest
Duck.ai (DuckDuckGo): a privacy-focused chat interface that gives you free access to six smaller models from third-party providers. No login or account required.
ERNIE 4.5 (Baidu): advanced, low-cost Chinese-English bilingual model with strong reasoning capabilities.
Gemma 3 (Google): a lightweight, open model family that can run on smaller devices, including smartphones.
Llama 4 (Meta): a family of open-weight models with native multimodal understanding.
Mistral Medium 3 (Mistral AI): low-latency, low-cost SOTA model for enterprise deployment.
Mistral Small 3.1 (Mistral AI): a fast, multimodal, multilingual open-source model with function calling.
What launched since our article:
Apertus (EPFL & ETH Zurich)
DeepSeek V3.2-Exp (DeepSeek)
Gemma 3 270M (Google)
Gemma 3n (Google)
Hunyuan-MT-7B (Tencent)
LFM2-VL (Liquid)
Lumo (Proton)
MAI-1-preview (Microsoft)
Mistral Medium 3.1 (Mistral)
Mu (Microsoft)
🧠 2. Reasoning models
Reasoning is no longer a novelty—every flagship launch ships chain-of-thought, tool use, and multi-step planning. Benchmarks are now neck-and-neck, but a few models still separate themselves on overall accuracy, latency, and price.
Top pick: o3/o3-pro (OpenAI)
o3-pro sits at (or tied for) the #1 intelligence slot on the latest Artificial Analysis leaderboard, with a max “Intelligence Index” score of 71 and a 128 k-token context window—plenty for day-long chats or document analysis.
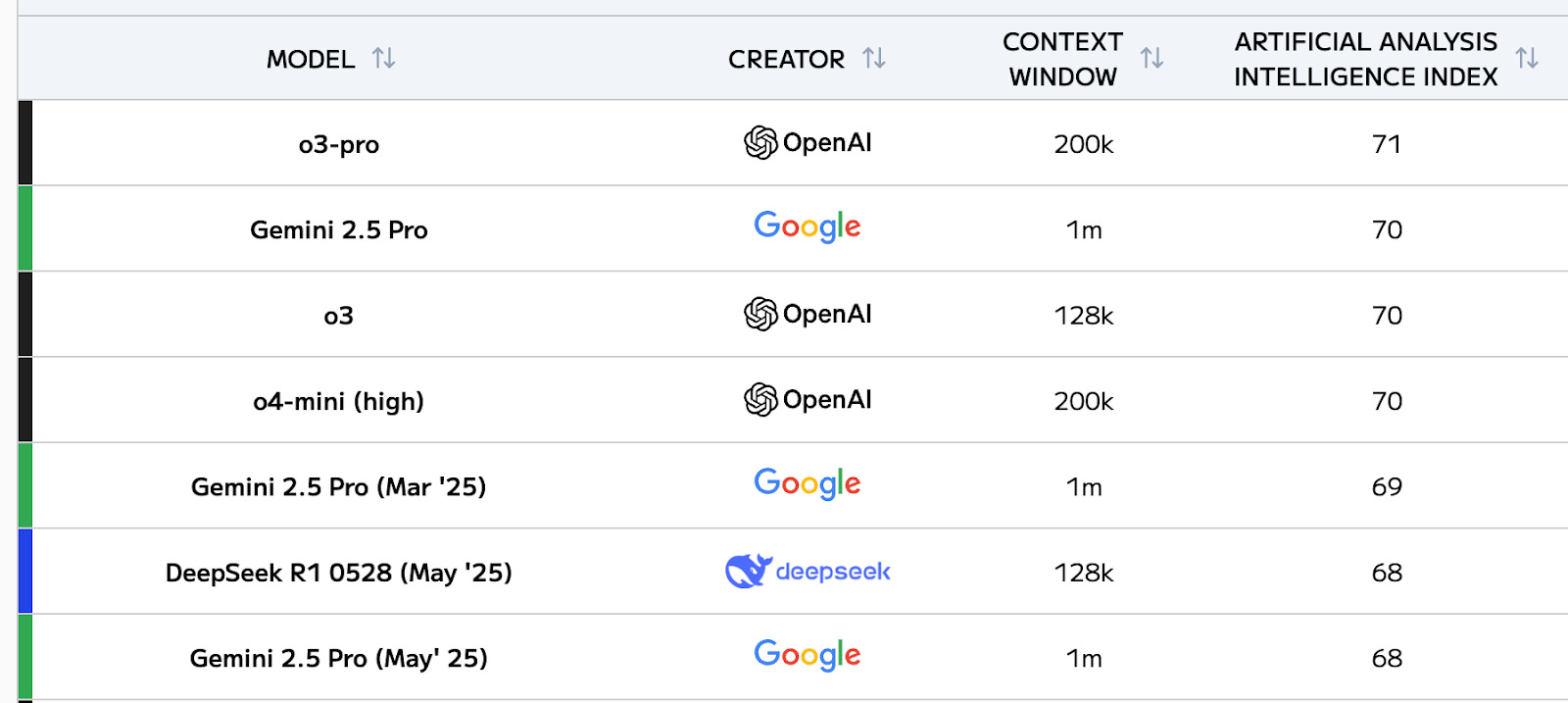
But given that it’s only available on the ChatGPT Pro plan, o3 is nearly as good in most situations, and has the ability to leverage tools like web search and deep research. Indeed, while other models may have larger context windows, o3’s tight ChatGPT integration makes it the top pick here.
Also great: Gemini 2.5 Pro (Google)
Google’s June-2025 refresh pushed Gemini 2.5 Pro to a 1,470 Elo on LM-Arena - neck and neck with o3. It leads several coding and long-form math benchmarks and enjoys the same million-token context window as earlier Gemini releases. If you live in Google Workspace, Gemini Pro’s tight Docs/Sheets integration may tip the scales.
All the rest
Claude 4 (Anthropic): excels at extended tool-use chains and multi-agent workflows; Opus 4 is Anthropic’s best coding/reasoning model yet.
DeepSeek R1 (DeepSeek AI): <$1 / M-token pricing with performance just a point or two below the leaders; the May 2025 “R1-0528” refresh improved math and logic.
Gemini 2.5 Flash (Google): Turbo-optimised sibling of Pro; fastest reasoning model on Artificial Analysis at 346 tokens / s, ideal for real-time agents.
Grok 3 (xAI): agent-centric design; Grok 3 (Think) hits 93 % on AIME-2025 and 84 % on GPQA with plenty of attitude to spare.
o4-mini (OpenAI): distilled o-series model optimised for speed/cost; reaches near-flagship AIME scores at a fraction of the price.
Qwen 2.5 (Alibaba): 20 T-token MoE pre-train delivers strong multilingual reasoning while staying inference-efficient
Qwen3-235B-A22B (Alibaba)
What launched since our article:
Claude Haiku 4.5 (Anthropic)
Claude Sonnet 4.5 (Anthropic)
Claude Opus 4.1 (Anthropic)
Deep Think (Google)
ERNIE X1.1 (Baidu)
ERNIE-4.5-21B-A3B-Thinking (Baidu)
Gemini 2.5 Flash-Lite (Google)
GLM-4.5 (Z.ai)
GLM-4.6 (Z.ai)
GPT-5 (OpenAI)
gpt-oss (OpenAI)
Grok 4 (xAI)
Hermes 4 (Nous Research)
Kimi K2 (Moonshot AI)
M1 (MiniMax)
M2 (MiniMax)
Magistral (Mistral)
Nemotron Nano 2 (NVIDIA)
Phi-4-mini-flash-reasoning (Microsoft)
Qwen3-Max (Alibaba)
Qwen3-Next (Alibaba)
Qwen3-Omni (Alibaba)
Reka Flash 3.1 (Reka)
Seed-OSS (ByteDance)
🔍 3. Research tools

These tools and features help you do heavy-duty research work on complex topics.
Top picks: Deep Research by either Google or OpenAI
Both of these tools work in a largely similar way:
Clarify the user’s request
Create a detailed research plan
Crawl multiple sources to collect information
Use a reasoning model to analyse the sources, identify gaps, and find additional information
Return a detailed report with citations
OpenAI’s version is powered by the o3 reasoning model, while Google’s runs on either 2.5 Flash (for free users) or 2.5 Pro (for paid accounts)
Try Google Deep Research (select “Deep Research” under the prompt box)
Try OpenAI Deep Research (select “Run deep research” in the “Tools” bar)
Best free tool: NotebookLM (Google)
NotebookLM remains the best free tool for making sense of unstructured information from multiple sources. This year, it added lots of new, highly useful features:
Automatically generated dynamic mind maps that help you explore your sources
Audio Overviews in multiple languages (not only English)
Customizable Video Overviews - animated slide decks from your content
“Discover sources” feature that lets you find new sources directly within NotebookLM
The ability to share your notebooks with others
All the rest
Genspark Super Agent (Genspark): an agent that orchestrates nine LLMs and 80+ tools to perform multistep research tasks and output information in different formats (learn more)
Perplexity (Perplexity AI): this year, the popular AI search engine added features like its own version of “Deep Research,” structured answer tabs, and agentic “Perplexity Labs”
Proxy (Convergence AI): a web-based agent especially well-suited for recurring tasks, letting you create templates and schedule jobs.
What launched since our article:
AI Sheets (Hugging Face)
AlphaEarth Foundations (Google)
Google Finance (Google)
Perplexity Patents (Perplexity)
Quick Suite (Amazon)
Qwen Deep Research (Alibaba)
Researcher Agent (Microsoft)
Web Guide (Google)
💻 4. Coding

AI coding is rapidly moving from “autocomplete on steroids” to autonomous agents that plan, edit, test, and even open pull requests for you (at a pace that, to be honest, scares me a little).
Overall best: Cursor (Cursor)
Cursor’s AI-native IDE keeps piling on agentic features: Background Agents that run long tasks asynchronously, BugBot for inline code review, one-click multi-repo MCP setup, and memories for persistent project context. Because it’s a full editor (not just an extension), Cursor can orchestrate file edits, terminal commands, and git ops in the same workspace - making it the most capable end-to-end coding agent today.
Also great: Claude Code (Anthropic)
Claude Code lives entirely in your terminal. It maps your repo, autocompresses context, and runs commands for you—so you focus on goals, not files. Recent releases added local filesystem access, MCP support, automatic diffs, and a GitHub Actions integration that lets you tag @claude on PRs for autonomous fixes.
All the rest
GitHub Copilot (GitHub/Microsoft): now ships an Agent mode that can take an issue, create a branch, implement the fix, and submit a PR—plus mobile support and Pro+ tier for model choice.
Google Jules (Google): asynchronous coding agent that clones your repo in a Cloud VM, crafts a plan, shows diffs, and submits a PR—powered by Gemini 2.5 Pro.
Junie (JetBrains): built into every JetBrains IDE, Junie navigates project structure, runs code/tests, and edits files autonomously; free tier now bundled with IDE licenses.
Replit Agent (Replit): type a natural-language spec and watch it scaffold, build, and deploy full apps in the browser—or from iOS/Android. Ideal for rapid prototyping.
Windsurf (Windsurf): AI-first IDE with “Flows” that blend copilot suggestions and fully autonomous agents; praised for speed and a generous free tier (and it’s reportedly being acquired by OpenAI, though it’s not publicly confirmed just yet).
What launched since our article:
AgentKit (Google)
Bugbot (Cursor)
Claude Code on the web (Anthropic)
Codestral 25.08 (Mistral)
CodeMender (Google)
Cursor 2.0 (Cursor)
Cursor Agent CLI (Cursor)
Devstral Small 1.1 & Devstral Medium (Mistral)
Genspark AI Developer (Genspark)
GPT-5 Codex (OpenA)
Grok Code Fast 1 (xAI)
Kiro (Amazon)
Lindy Build (Lindy)
Opal (Google)
v0.app (Vercel)
🌐 5. Browser agents
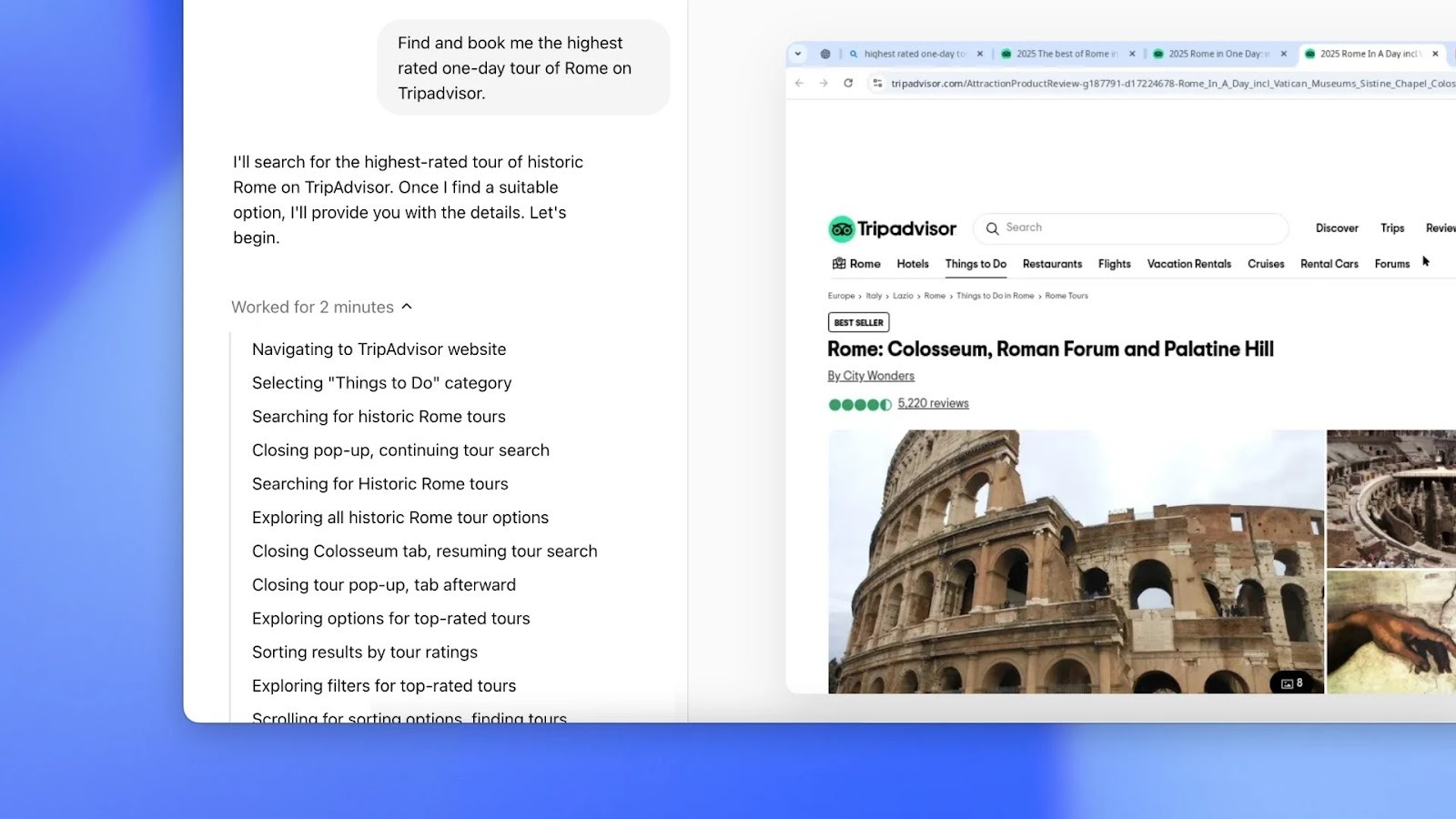
Autonomous browser-controlling agents are the new hotness - clicking, typing, and scrolling for you when no API exists. Benchmarks such as WebArena and WebVoyager are the scoreboards, but real-world usability still varies a lot.
Overall best: Operator (OpenAI)
OpenAI’s research-preview agent “Operator” uses a Computer Use Agent (CUA) model to see screenshots, reason step-by-step, and act on the web. Tight ChatGPT integration, saved workflows, and multi-task tabs make it the easiest place to start. And although it leads the pack on benchmarks currently, its performance still leaves much to be desired.
Runner up: Manus
Manus prioritizes speed and long-form autonomy: you hand it a complex job (“compare 10 insurance policies, compile a deck”) and watch it zip through multiple tabs in real time. Early users praise its fast ReAct loops and credit-based pricing, though access is still gated.
All the rest
Browser Use (Browser Use): open-source library + cloud service that achieves 89 % on WebVoyager and powers many DIY agents.
Computer Use (Microsoft): built-in Copilot Studio and aimed at letting low-code builders embed UI automations across browsers, this is a great enterprise option.
Dia (The Browser Company): successor to Arc - a standalone “AI browser” now in closed alpha that interprets the whole window and executes natural-language commands such as “fill cart and checkout.”
Opera Browser Operator (Opera): a native agent in the Opera browser that runs scripted tasks while keeping you logged in.
Project Mariner (Google): Chrome-sidebar agent born at DeepMind; autonomously navigates and completes up to a dozen tasks per run, topping recent WebArena scores (while tempting to include this as the top pick, I haven’t been able to test it personally)
What launched since our article:
ChatGPT agent (OpenAI)
ChatGPT Atlas (OpenAI)
Comet Browser (Perplexity)
Copilot Mode (Microsoft)
Director (Browserbase)
Gemini 2.5 Computer Use (Google)
Genspark AI Browser (Genspark)
Manus 1.5 (Manus)
Opera Neon Browser (Opera)
Windsurf Browser (Windsurf)
🖼️ 6. Image models & platforms
These services let you create and edit images using AI.
Top pick: GPT-4o native image creation (OpenAI)
Quite simply, GPT-4o native image generation is currently the #1 image model in the world:
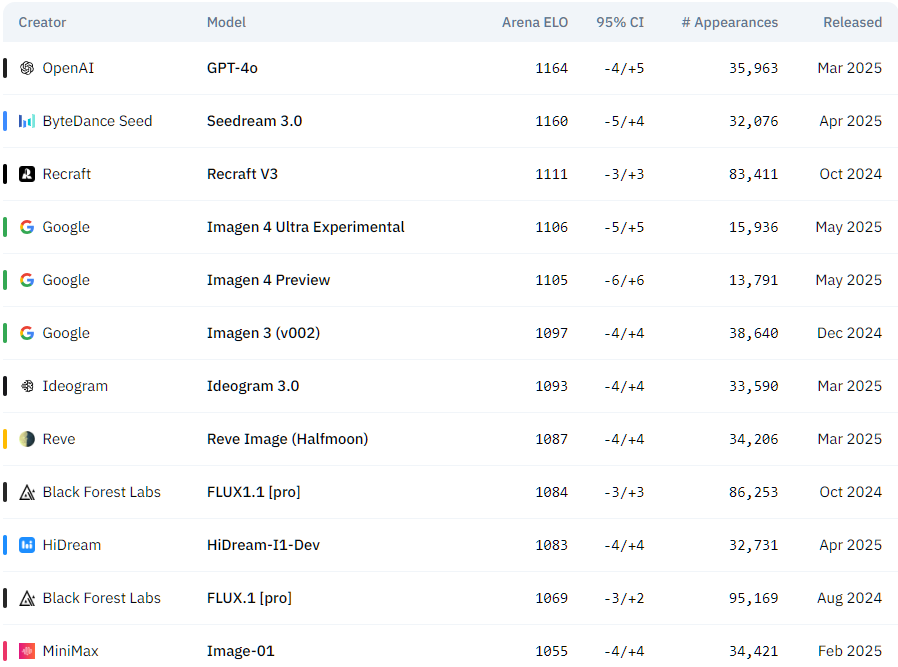
It was initially only available to paying ChatGPT subscribers via chatgpt.com or sora.com. But as of mid-May, you can use GPT-4o image generation for free in Microsoft Copilot.
GPT-4o is context-aware, can mimic any style from photographic to artistic, and render entire pages of error-free text inside an image.
There are dozens of use cases for GPT-4o native image generation.
What will you use it for?
Also great: Imagen 4 (Google)
Imagen 4 only came out in late May 2025 and is a fantastic model in its own right.
It’s only a hair behind GPT-4o in terms of output quality but can pump out images many times faster:
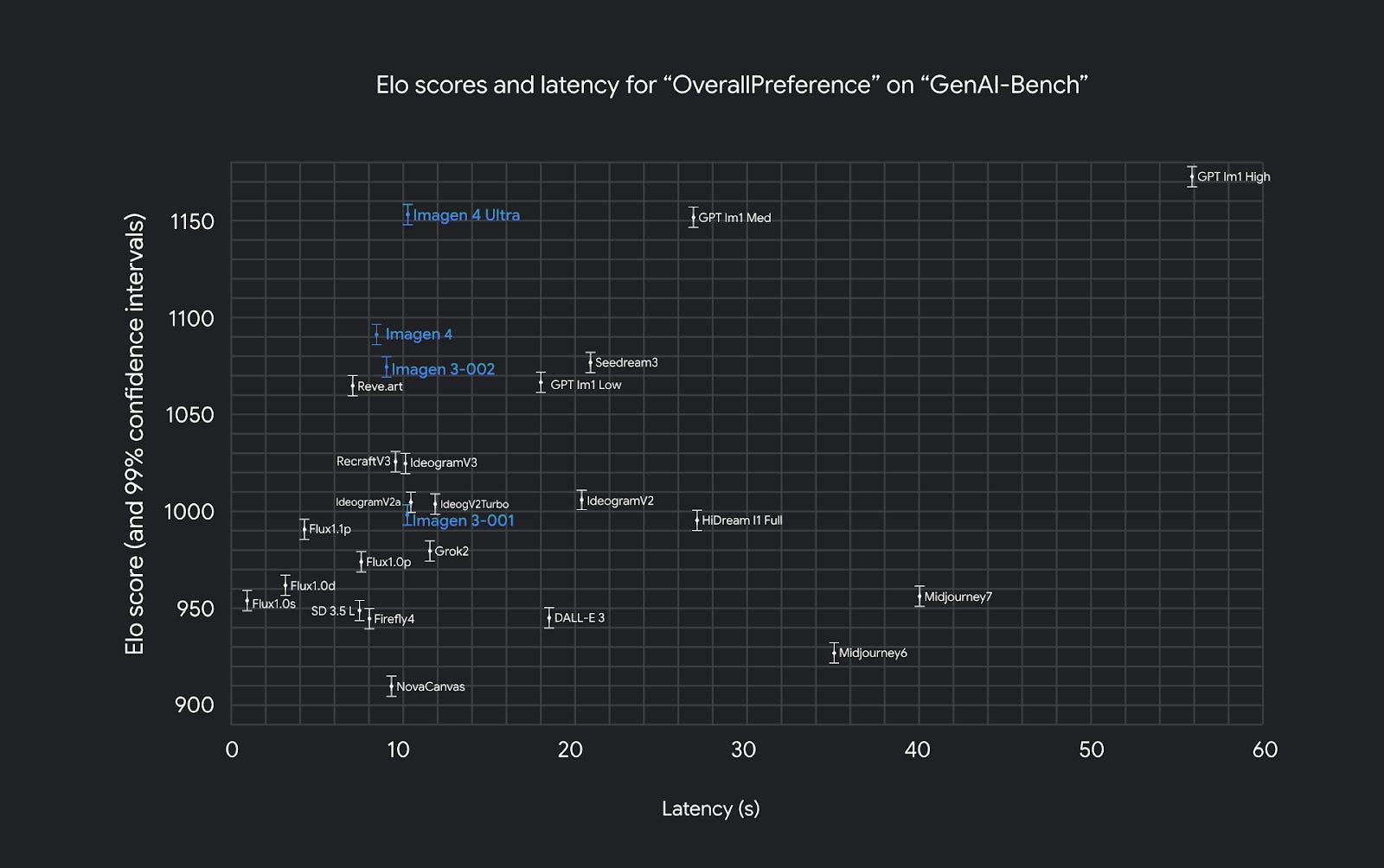
The best part is that Imagen 4 is free to try for all users inside the following Google products:
All the rest:
Canva Visual Suite 2.0 (Canva): an integrated suite of AI-powered visual tools and features to assist with any design task.
Firefly Image 4 (Adobe): commercially safe text-to-image model trained exclusively on licensed and public domain data.
FLUX.1 Kontext (Black Forest Labs): an impressive multimodal image model that can make targeted, in-context image edits based on both text and image inputs.
Gemini 2.0 Image Generation (Google): native image generation model for fast, iterative image creation and editing via conversational inputs.
Ideogram 3.0 (Ideogram AI): image model that can create realistic visuals with accurate text and offers customizable styles from reference images and style presets.
KREA (Krea AI): a one-stop creative playground that lets you generate images, 3D assets, videos, and more using top models from third-party providers.
Midjourney V7 Alpha (Midjourney Inc.): highly personalizable model with better image quality and a lightning-fast Draft Mode for iterative prompting.
Reve Image 1.0 (Reve AI): text-to-image model that excels at prompt-adherence, aesthetics, and typography. (Although it didn’t do that great in my hands-on test.)
Seedream 3.0 (ByteDance): lightning-fast, top-tier model with native 2K output and best-in-class text rendering (including Chinese).
What launched since our article:
Acrobad Studio (Adobe)
Firefly Boards (Adobe)
Firefly Image Model 5 (Adobe)
Gemini 2.5 Flash Image (aka “Nano Banana”) (Google)
Genspark Photo Genius (Genspark)
Higgsfield Canvas (Higgsfield AI)
HunyuanImage-2.1 (Tencent)
Ideogram Character (Ideogram)
Ideogram Styles (Ideogram)
Image Reference Tool (Higgsfield AI)
KOLORS 2.1 (Kling AI)
Kontext Komposer (Black Forest Labs)
Krea 1 (Krea AI)
MAI-Image-1 (Microsoft)
Mixboard (Google)
Pomelli (Google)
Qwen-Image-Edit (Alibaba)
Qwen-VLo (Alibaba)
Reve Image Update (Reve)
Seedream 4.0 (ByteDance)
Soul (Higgsfield AI)
USO (ByteDance)
📹 7. Video generation
Video is perhaps the busiest AI scene of 2025, with dozens of new entrants and massive leaps in output quality. (To wit: One week after this section was first drafted, three new video models launched and had to be incorporated.)
Best paid model: Veo 3 (Google)
Veo 3 is a major paradigm shift in AI video.
The model natively creates video and audio simultaneously from a simple text prompt.
The results are scarily realistic, with the now-infamous “emotional support kangaroo” video fooling otherwise skeptical people.
The recently released Seedance 1.0 now sits above the no-audio version of Veo 3 on the Artificial Analysis Video Leadeboard:
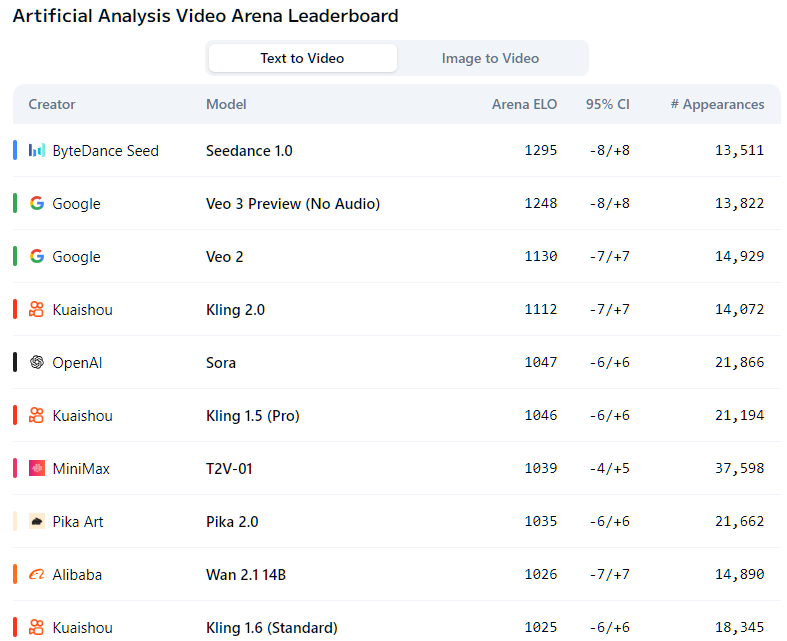
But when you consider the combined video+audio package, Veo 3 is hard to beat!
Veo 3 requires a Google AI Pro or Ultra account and can be accessed via gemini.google.com or Google’s new film-making platform, Flow
Best open-source model: Wan 2.1 VACE (Alibaba)
Alibaba’s Wan 2.1 VACE is publicly available as an open-source model that can run on devices with just 8GB of video RAM.
It’s also competitive with many top-tier closed models like Kling, Sora, and Hailuo.
You can download the model on Hugging Face or try it at wan.video.
All the rest:
Amazon Nova Reel 1.1 (Amazon): Amazon’s enterprise-focused video generation.
AvatarFX (Character.ai): bring images to life and create talking avatar videos with realistic facial expressions. (Join waitlist.)
Hailuo 02 Video Gen (MiniMax): Fresh model with best-in-class instruction following, native 1080p resolution, and capable of accurately rendering highly complex movements.
Hedra Character 3 (Hedra): create expressive animated characters from images, text, and audio.
HeyGen Avatar IV (HeyGen): a professional model for creating personalized speaking avatars from photos.
Higgsfield DoP I2V‑01‑preview (Higgsfield AI): image model with action effects and advanced, cinematic camera controls.
HunyuanVideo I2V (Tencent): Tencent’s image-to-video model with motion consistency and realism.
Kling 2.1 (Kuaishou): Kuaishou’s latest video generation model with improved dynamics, better prompt adherence, and 1080p output.
LTX Studio 0.9.5 (Lightricks): a comprehensive video production platform that combines multiple third-party AI video tools in one interface.
Luma Ray 2 (Luma AI): physics-aware video generator that excels at realistic visuals and coherent motion.
Midjourney V1 Video Model (Midjourney): Midjourney’s first entry into the AI video scene, this image-to-video model can animate static Midjourney images.
OmniHuman-1 (ByteDance): create realistic talking videos from a single image and audio/video input.
Pika 2.2 (Pika Labs): the latest model from Pika with 1080p output and Pikaframes for controllable keyframe transitions.
Pixverse V4.5 (Pixverse): cinematic output with 20+ camera controls, fusion of multiple reference elements, and smooth motion handling.
Runway Gen‑4 (Runway): top-tier model integrated into Runway’s all-in-one platform with professional editing and film-making features.
Seedance 1.0 (ByteDance): Currently the best-ranked text-to-image model in the world, capable of multi-shot video generation at native 1080p resolution.
SkyReels V2 (SkyReels): an open-source, infinite-length video generation model for long-form AI videos. Integrated into the SkyReels all-in-one platform.
Vidu Q1 (Shengshu Technology): Vidu’s latest model with sharper visuals, smoother transitions, more expressive animations, and perfectly timed sound effects.
Whisk Animate (Google): turn your Google Whisk creations into short video clips using Google’s Veo 2 video model. (Here’s a “Getting Started” guide to Whisk.)
What launched since our article:
Act-Two (Runway)
Aleph (Runway)
Androidify (Google)
Digital Twin (HeyGen)
Genspark Clip Genius (Genspark)
Grok Imagine (xAI)
Hailuo 2.3 (MiniMax)
Hailuo Video Agent (MiniMax)
HD mode for video (Midjourney)
Higgsfield Ads 2.0 (Higgsfield AI)
Kling 2.5 Turbo (Kling AI)
Kling Avatar (Kling AI)
Krea Realtime 14B (Krea AI)
lipsync-2-pro (Sync Labs)
LTX-2 (LTX Studio)
Marey (Moonvalley)
Matrix-Game (Skywork AI)
MirageLSD (Decart)
Odyssey-2 (Odyssey ML)
PixVerse V5 (PixVerse)
Ray3 (Luma AI)
Sora 2 (OpenA)
Veo 3 Fast (Google)
Veo 3.1 (Google)
Wan 2.5 (Alibaba)
Wan-S2V (Alibaba)
🎶 8. Music creation

The AI music space didn’t see too many new launches.
(Notably, the last major release from Udio was back in July 2024.)
Still, there are a couple of things worth highlighting.
Top pick: Suno 4.5 (Suno AI)
Suno remains the leader in AI music.
The recently released Suno 4.5 model features enhanced vocals, better prompt adherence and genre mashups, more complex sounds, and faster generations, among other things.
On top of that, Suno’s been improving the platform itself. In January, Suno launched “Workspaces” to help creators better organize their work. In early June, the upgraded Song Editor came out that can edit tracks with precision, extract stems, use upload reference audio, and much more.
All of this makes Suno an unbeatable package if you’re looking to create music with AI.
All the rest
FUZZ (Riffuson) - while not quite as high-quality as Suno 4.5, Riffusion lets you generate unlimited songs using its basic models and remix existing tracks.
Lyria 2 (Google DeepMind) – unlike Suno, Udio, and Riffusion, Google’s music model is focused on producing professional-quality instrumentals rather than entire songs.
What launched since our article:
Eleven Music (ElevenLabs)
Music 1.5 (MiniMax)
Stable Audio 2.5 (Stability AI)
Suno v5 (Suno)
Video-to-Music (ElevenLabs)
Voices (Udio)
🎤 9. Voice & sound
For most of 2025, the voice-AI landscape felt subdued - incremental tooling upgrades but few headline-grabbing models. But one choice really stood out here.
Best Overall: ElevenLabs v3 (ElevenLabs)
ElevenLabs’ v3 model, dropped into public alpha in early June, keeps the studio-quality realism (and internationalization) that made the brand famous while adding a huge boost in expressiveness and steering. Inline audio tags let you tweak emotion, pitch, pacing, and even add SFX without touching an editor.
All the rest
Chirp 3 (Google Cloud): “instant custom voice” that trains a bespoke speaker from minutes of audio and streams TTS with sub-300 ms latency.
OpenAI Realtime Audio (OpenAI): low-latency speech-to-speech and characterful TTS available through the new Realtime API.
Octave (Hume AI): emotion-aware TTS that lets you prompt styles like “whisper fearfully” or “sound sarcastic” and nails the delivery.
Nova Sonic (Amazon): a unified speech-in, speech-out model for real-time conversational agents on Bedrock.
Voicebox 2 (Meta): zero-shot multilingual TTS that clones a voice from a 2-second sample and generates speech 20× faster than autoregressive models.
What launched since our article:
11ai (ElevenLabs)
EVI 3 voice cloning (Hume AI)
Genspark AI Pods (Genspark)
gpt-realtime (OpenAI)
HunyuanVideo-Foley (Tencent)
Inworld TTS (Inworld AI)
MAI-Voice-1 (Microsoft)
Octave 2 (Hume AI)
SFX v2 (ElevenLabs)
Speech 2.6 (MiniMax)
Qwen3-TTS-Flash (Alibaba)
VibeVoice (Microsoft)
Video-to-Sound (ElevenLabs)
Voice Design (MiniMax)
🧊 10. Text-to-3D object & world generators

2025 finally made text-to-3D practical: seconds-to-minutes generation, built-in texturing, even one-click rigging. Quality still varies, and access ranges from open research code to slick web apps - but a few tools clearly lead the pack.
Top pick: Meshy AI (Meshy)
Meshy pairs fast, two-stage diffusion with a friendly web IDE: you type a prompt, get four previews in seconds, then upscale the favorite into a full, UV-mapped mesh (usually ≤ 2 minutes). It auto-unfolds UVs, applies PBR textures, and can auto-rig characters to a biped or quad skeleton for instant animation tests. A generous free tier (200 credits/mo) plus paid plans makes it the most capable and accessible end-to-end pipeline in 2025.
Best free tool: Rodin (Hyper3D)
Rodin is a zero-cost web app that turns text or images into detailed, game-ready meshes with clean topology in ~30 s. It excels at hard-surface props and offers one-click remesh/optimize functions. Users praise its speed and “no limits” pricing—perfect for indies or students who want unlimited experiments without a GPU bill
All the rest
3D AI Studio (3D AI Studio): all-in-one web suite (text/image-to-3D, text-to-image, voxel mode) with sub-$10 credit plans; quality on par with Meshy, but no free tier.
Luma Genie (Luma Labs): whimsical, highly creative generator that shows four drafts in seconds, then refines the chosen one in 5-20 min; completely free but limited daily slots - great for concept art, less so for realism.
Meta 3DGen (Meta): two-stage AssetGen + TextureGen system that pro artists preferred in blind tests.
Trellis (Microsoft Research): a solid open-source model that delivers benchmark-leading fidelity while generating much faster than older diffusion pipelines.
What launched since our article:
AI Blueprint for 3D objects (NVIDIA)
AI World Creator (Exists)
Copilot 3D (Microsoft)
Genie 3 (Google)
HunyuanWorld-Voyager (Tencent)
Hunyuan World 1.0 (Tencent)
Seed3D 1.0 (ByteDance)
WorldLabs 3D upgrade (World Labs)
🫵 Over to you…
Which of these are you already familiar with? Which ones are in your toolbox? Have we missed any major models or products in our roundup?
Leave a comment or drop me a line at whytryai@substack.com.
Thanks for reading!
If you enjoy my writing, here’s how you can help:
❤️Like this post if it resonates with you.
🔄Share it to help others discover this newsletter.
🗣️Comment below—I love hearing your opinions.
Why Try AI is a passion project, and I’m grateful to those who help keep it going. If you’d like to support my work and unlock cool perks, consider a paid subscription:
Qwen Deep Research, that is pretty neat.
This article comes at the perfect time! What a brilliant and much-needed roundup. The intense pace of generative AI releases you highlighted is truly wild. I'm curious, how do you even begin to evaluate what's genuinly groundbreaking versus a minor iteration, given tools are surpassed so quickly?